
목록Career/알고리즘 · 자료구조 (28)
나무 숲
 [C++ STL] #include<queue>
[C++ STL] #include<queue>
C++에서 제공하는 큐 라이브러리 사용법입니다. 선입선출(FIFO) 방식의 큐입니다. 사용 #include queue Q //Q라는 이름의 int 요소들로 구성된 큐 선언 Q.push(값) //큐 Q에 값을 넣는다. 리턴 값이 없다. Q.pop() //큐 Q의 front를 삭제한다. 리턴 값이 없다. Q.front() //큐 Q의 front를 리턴한다. front는 삭제되지 않는다. (peek기능) Q.back() //큐 Q의 back를 리턴한다. back는 삭제되지 않는다. (peek기능) Q.size() //큐 Q의 크기(구성 요소 갯수)를 리턴한다. Q.empty() //큐 Q가 비어있으면(요소가 없으면) 를 1(True)리턴하고 비어있지 않으면 0(False)를 리턴한다. 예제 코드#include..
 [C++ STL] #include<stack>
[C++ STL] #include<stack>
C++에서 제공하는 스택 라이브러리 사용법입니다. 후입선출(LIFO) 방식의 스택입니다. 사용 #include stack S //S라는 이름의 int 요소들로 구성된 스택 선언 S.push(값) //스택 S에 값을 넣는다. 리턴 값이 없다. S.pop() //스택 S의 top을 삭제한다. 리턴 값이 없다. S.top() //스택 S의 top을 리턴한다. top은 삭제되지 않는다. (peek기능) S.size() //스택 S의 크기(구성 요소 갯수)를 리턴한다. S.empty() //스택 S가 비어있으면(요소가 없으면) 를 1(True)리턴하고 비어있지 않으면 0(False)를 리턴한다. 예제 코드#include #include int main(){ std::stack S; std::cout
EOFEnd Of File파일의 끝을 의미하는 상수(-1)윈도 콘솔 창에서는 ctrl+z의 입력을 의미 %lfdouble형 변수를 입력받기 위해 fflush(stdin)입력 버퍼를 비운다 NULL 의 아스키: 0
 이진 트리 (Binary Tree) - 소개
이진 트리 (Binary Tree) - 소개
* 책 열혈강의 + 인터넷 트리 Tree 비선형 자료구조마치 조직도같은 모양! 용어 Node 노드 : 데이터를 저장하는 각각의 요소 Root Node 루트 노드 : 트리 구조의 최상위 노드 Terminal Node 단말 노드 : 아래로 다른 노드가 연결되어 있지 않은 노드 Internal Node 내부 노드 : 단말 노드를 제외한 노드 Edge 간선 : 노드를 잇는 선 관계 Parent 부모 : 자식 노드를 가진다 Child 자식 : 부모 노드를 가진다 Sibling 형제 : 같은 부모로부터 형제 노드를 가진다 (위 그림에서는 같은 색깔끼리 관계를 형성) Level 레벨 : 트리의 가장 위에서부터 (0) 층별로 매겨진 숫자 Height/Depth 높이/깊이 : 트리의 최고 레벨. 위 그림에서는 2 Deg..
arr=['a', 'b', 'c'] 일 때 print arr 하면['a', 'b', 'c']이렇게 나온다. 이것을 abc로 나타내고 싶다면print ''.join(arr)이라고 한다. 마찬가지로 arr2 = [1, 2, 3] 일 때print arr2 하면[1, 2, 3] 이라고 나오는데 123으로 나타내고 싶다면print ''.join(str(x) for x in arr2)라고 한다.''.join(map(str, arr2))이것도 가능하다. +)TypeError: 'int' object has no attribute '__getitem__'라는 에러를 마주쳤는데,str1="abc"와 str2="def" 이 두 문자열을 한 char씩 비교하려고 하니까 나타났다. (str1[0]==str2[0])int랑 딱..
 큐 (Queue)
큐 (Queue)
큐큐는 선착순에 비유할 수 있다.먼저 온 사람이 먼저 들어가는 것처럼, 큐라는 자료구조 안에서는 먼저 들어온 데이터가 먼저 나간다.이러한 구조를 FIFO (First-In, First-Out. 선입선출)라고 한다.빈 큐. 큐에서는 앞부분, 즉 머리를 Front로 나타내고 뒷부분, 즉 꼬리를 Rear로 나타낸다. 데이터를 넣은 모습. (enqueue)데이터가 하나뿐이므로 데이터=front=rear이다.데이터를 이렇게 더 채워넣은 상태에서 데이터 삭제 함수(dequeue)를 호출하면 가장 앞의 데이터가 빠져나간다. 따라서 front는 2라는 값을 가진 노드를 가리키게 된다. 양방향 연결 리스트로 구현하였습니다~ (거꾸로도 출력할 수 있어서..)연결 리스트를 이용한 큐 구현0 구조체 정의+초기화 #includ..
 스택 (Stack)
스택 (Stack)
(사실 스택과 큐는 C++에서 #include #include 그리고 자바에서 java.util.stack java.util.queue 을 이용하여 직접적인 구현 없이 사용이 가능합니다) 스택 Stack을 한국어로 번역하면 쌓다, 입니다. 이름에서도 알 수 있듯이 데이터를 접시처럼 쌓고, 맨 아래 접시부터 빼면 접시가 무너지기에.. 접시를 사용하려면 맨 위 접시(데이터)를 빼내야 합니다. 이렇게 나중에 들어간 것이 먼저 나오는 구조를 LIFO (Last-In First-Out. 후입선출) 구조라고 합니다. 빈 스택입니다. 맨 위를 top, 맨 아래를 bottom이라고 합니다. 스택에 데이터를 넣는 것을 push라고 합니다. 위 그림은 데이터가 하나뿐이므로 데이터=top=bottom인 상태입니다. 데이터가..
 연결 리스트 (Linked List) - 이중 연결 리스트, 이중 원형 연결 리스트
연결 리스트 (Linked List) - 이중 연결 리스트, 이중 원형 연결 리스트
이중 연결 리스트 Double Linked List 이중 연결 리스트입니다. 일반 연결 리스트와 다르게 한 노드를 기준으로 그 전 노드를 가리키는 before, 그 다음 노드를 가리키는 next 포인터가 존재합니다. 첫 번째 데이터가 tail에 삽입된 모습입니다. 노드가 하나뿐이라 head=tail=뉴노드 입니다. 뉴노드를 삽입하는 모습입니다. 뉴노드의 next은 (헌)노드, (헌)노드의 before는 뉴노드 입니다. 이후 뉴노드는 tail이 됩니다. head는 그대로인 모습입니다. 노드를 삭제하는 모습입니다. 더미노드를 만들어 삭제할 부분인 tail를 가리키게 합니다. tail는 tail->before을 가리킵니다. 삭제될 노드를 가리키는 tail->next는 NULL이 됩니다 더미노드의 메모리를 해제..
 연결 리스트 (Linked List) - 원형 연결 리스트
연결 리스트 (Linked List) - 원형 연결 리스트
* 열혈강의 자료구조 책 + 인터넷 + a 원형 연결 리스트 Circular Linked List 원형 연결 리스트입니다.그림처럼 하나로 쭉 이어지며, tail이 별도로, 반드시 필요하지는 않습니다.head와 tail을 구분지어서 tail과 tail->next(head)로 사용하는 경우도 있습니다.저는 구분짓지 않고 head만을 사용하였습니다. (따라서 마치 tail과도 같은 역할을 수행하게 되었습니다..) 리스트가 텅 빈 상태에서 뉴노드를 넣게 되면 보여지는 모습입니다 노드가 하나 이상일 때 노드를 추가하면 나타나는 모습입니다.이러한 구조 때문에 head부터 리스트의 데이터들을 출력하면 생각하던 결과와 다소 다른 값이 출력됩니다.출력값은 아래 스크린샷에 있습니다. (1에서 5.. 순서대로 출력하려면 h..
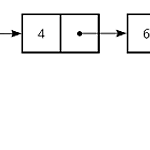 연결 리스트 (Linked List) - 메모리의 동적 할당
연결 리스트 (Linked List) - 메모리의 동적 할당
* 열혈강의 자료구조 책 + 인터넷 + a 연결 리스트란? (메모리의 동적 할당) 메모리의 동적 할당, 즉 malloc와 free를 이용한 연결 리스트의 핵심 중 하나는 바로 아래 코드입니다 #include using namespace std; typedef struct _Node{ int data; struct _Node *next; } Node; Node 구조체입니다. 여기서 Node란, data, 즉 어떤 값을 가지고 있으며, 동시에 Node형 구조체 변수의 주소 값을 저장할 수 있는 포인터 변수를 포함합니다. (책에서는 바구니에 비유) 더 단순하게 이해해보자면 Node의 값은 data, 그리고 다음 Node의 주소는 next에 있다. 즉 data라는 값을 가진 노드 하나는 next 노드를 가리킨다..
 연결 리스트 (Linked List) - 배열
연결 리스트 (Linked List) - 배열
* 열혈강의 자료구조 책 + 인터넷 + a책이 정말 너무 잘 되어있지만 여기엔 간단하게 씀 + 내상각 추가 순차 리스트 (배열 기반) 순차적으로 접근할 수 있는, 구조체와 배열을 이용한 연결 리스트이다. 1. 배열 기반의 구조체 정의 typedef struct _ArrayList{ int arr[100]; int numOfData; //데이터의 개수 int curPosition; //배열의 인덱스 값 저장 } List; //구조체 이름을 List로 정의 2. 구조체 기반 함수 정의(기능 위주)void ListInit(List *list){ //리스트 초기화 list->numOfData = 0; //리스트에 저장된 내용이 없다 list->curPosition = -1; //아무것도 저장하지 않음을 의미 }..
 하노이 타워 (The Tower of Hanoi)
하노이 타워 (The Tower of Hanoi)
조건 - 원반은 한 번에 하나만 옮길 수 있다 - 작은 원반 위에 큰 원반을 올릴 수 없다 패턴 분석 C를 3으로 옮기고자 할 때, A와 B를 2에 옮겨 놓으면 가능하다. -> B를 2로 옮기고자 할 때, A를 3에 옮겨 놓으면 가능하다. 이번엔 4개 (위에서부터 아래로 A,B,C,D) D를 3으로 옮기고자 할 때, A,B,C를 2로 옮겨 놓으면 가능하다. -> C를 2로 옮기고자 할 때, A,B를 3으로 옮겨 놓으면 가능하다. -> B를 3으로 옮기고자 할 때, A를 2로 옮겨 놓으면 가능하다. ... 같은 방식으로 몇 개의 원반이 있던 간에 어떠한 동일 패턴이 존재한다는 것을 알 수 있다. 이를 다시 일반적으로 표현해보면, n개의 원반이 있다고 할 때 (위에서부터 아래로 1,2...n번째) 1~(n-..
 이진 탐색 (Binary Search)
이진 탐색 (Binary Search)
자료구조의 목적은 데이터를 효율적으로 저장하는 데 있다 이러한 자료구조를 기반으로 작성된 알고리즘은 메모리와 속도를 고려하게 되는데 우리가 더 관심있게 보는 것은 속도이다. 순차 탐색 알고리즘(배열의 첫 번째 원소부터 순서대로 탐색)보다 훨씬 좋은 성능을 보인다 단!!! 배열에 저장된 원소는 정렬되어 있어야 한다 방법 1 배열의 중앙(배열 길이가 n이라고 할 때, (처음0 + 끝n-1)/2)에 찾는 값이 저장되어 있는지 확인 2 만약 아닐 경우, 찾는 값과 배열의 값을 비교하여 찾고자 하는 값이 배열의 값보다 작으면, 배열의 값을 기준으로 오른쪽에 있는 원소들로 탐색 범위 제한 마찬가지로, 배열의 값보다 찾고자 하는 값이 크면, 배열 값 기준으로 왼쪽에 있는 원소들로 탐색 범위 제한 (오름차순 일 때!)..